Nominees
Using the current communication channels, researchers spend a lot of time on reading and assessing the information about relevant scientific events, research projects, and tools. Additionally, important and related information might be overlooked because of the vast amount of information announced every day. To provide comprehensive information about different, currently underserved aspects of scientific communication such as scientific events, journals, projects, organisations, research schools, funding sources and available tools, we present OpenResearch.org. OpenResearch [1] is a platform for ingesting and crowd-sourcing of semantically structured information related to research that helps researchers of any field to collect, organize, share and disseminate such information. Already now OpenResearch comprises comprehensive data about 3.946 Conferences, 867 Workshops, 307 Event series and 5.156 researchers.
OpenResearch enables a collaborative management of scholarly communication metadata with a current focus on scientific events such as conferences, workshops, summer schools. OpenResearch aims to:
1. reduces the effort for researchers to find ‘suitable’ events (according to different metrics) to present their research results,
2. enables exploring person roles in events and organizations,
3. supports event organizers in visibly promoting their event with less effort,
4. establishes a comprehensive ranking of events by quality and structure such as event series, sub-events and event sessions,
5. provides a cross-domain service recommending suitable submission targets to authors, and
6. supports easy and flexible data exploration using Linked Data technology: a structured dataset of conferences facilitates selection regarding fields of interest or quality of events.
Driven by Semantic MediaWiki (SMW), OpenResearch provides a user interface for creating and editing semantically structured event descriptions (e.g. call for papers). It uses a comprehensive ontology to capture semantic descriptions of events that allow automated data collection from conference websites aligned with schema.org. We are reusing existing vocabularies from related domains that increase the value of semantic data. In addition to data curation using semantic forms and templates of SMW that allows event organizers and researchers to insert data into OR, an automated approach is implemented for data acquisition from other sources such as portals and services containing related data. We are using bulk import of SMW to insert the collected data at once.
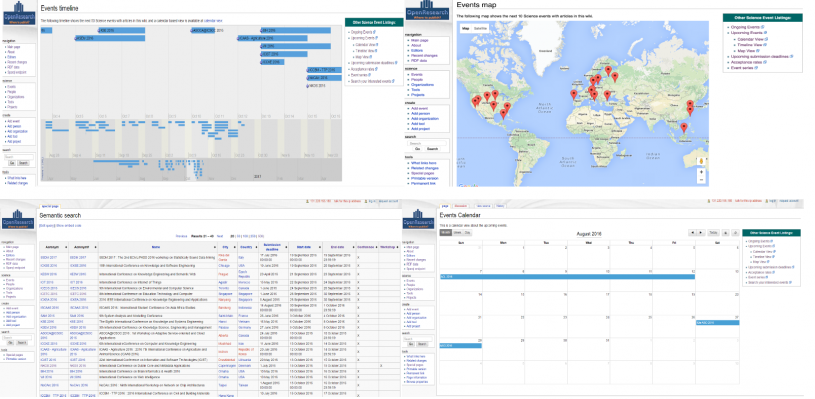
A semantic wiki page is created for each individual event. In additions, several extensions of the SMW are used to represent information such as map view of the upcoming events using location-based filtering, calendar and time-line visualizations. Furthermore, OR enables quality-related queries over a multidisciplinary collection of events according to a broad range of criteria such as acceptance rate, sustainability of event series, and reputation of people and organizations. The queries can be defined and executed using all defined properties and classes and the results can be embedded in wiki pages. This builds a list of new indicators for measuring the quality and relevance of research.
Due to heterogeneous and multidisciplinary nature of science, publishing culture as well as research needs vary in different research domains. For example, medicine researchers often publish the research results in journals in contrast to computer science that events play an important role. As a results, researchers of different fields need to look for different publishing medium in different sources. However, the difficulty of finding such information remains the same for all domains. The focus of this project is the development of a comprehensive and easy-to-use channel to better support the researchers of any domain regardless of their publishing culture. We see OR as a first step towards tighter interlinking and integrating of open services for scholarly communication. OR aims to provide services for various stakeholders of scholarly communication including researchers as well as event organizers, sponsors, publishers, event PC members and developers, etc. For example, one of the difficult and time-consuming tasks for event organizers is to collect a group of high-profile researchers as PC members or to find local and international sponsors. Interlinking OR LOD with datasets including author and person information or organizations and companies can help in this regard. We envision that data flows and service integration between OR and other open scholarly services is greatly intensified. In particular, we plan to relate events with other entities e.g., publications, projects, datasets and build recommendation services on top of the collected data.
All components of scientific communication need to be open and easily accessible. OpenResearch is part of a greater vision towards enabling true open access not just from a legal but from a technical perspective, and is aligned with OpenAIRE project, the Open Access Infrastructure for Research in Europe. It will truly support and accelerate Open scientific communication, of which Open Data and Open Access are of fundamental importance. In this regard, all data created within OpenResearch is published as Linked Open Data (LOD) and licensed under CC-BY-SA. We so far provide the following ways of accessing the OR LOD: a) downloadable RDF dump [2] with weekly updates, b) a SPARQL endpoint [3].
[1] OpenResearch website: http://openresearch.org/
[2] OpenResearch RDF dump: http://openresearch.org/Special:ExportRDF
[3] OpenResearch SPARQL endpoint: http://openresearch.org:9999/blazegraph/#query